
Embodied AI for Vision Language Navigation (VLN) with Quadruped Robots
Published in Github Repo, 2025
Links
- Paper: Advancing Vision-Language Navigation for Quadruped Robots
- Poster: Poster
- Code: FYP-Navigator GitHub Repository
- Video: Presentation
This project draws inspiration from pioneering works in Vision-Language Navigation (VLN), notably the NaVILA and Recurrent-VLN-BERT. These efforts motivated our focus on adapting VLN frameworks for the unique dynamics of quadruped robots. Additionally, ChatGPT was used in polishing this document.
Embodied AI for Navigation with Quadruped Robots
Author: Wong Lik Hang Kenny
GitHub Repository: FYP-Navigator
Related Repositories:
- Dataset: VLN-Go2-Matterport
- Main Model: Recurrent-VLN-Bert-Isaac
- LLM Case Study: MCoT-LLM-VLN

Figure 1: Quadruped robot navigating in the simulator (Isaac Sim).
Abstract
Embodied Artificial Intelligence (Embodied AI) enables robots to perceive and interact with their environments, with Vision-Language Navigation (VLN) as one of the most critical downstream tasks where robots are required to follow language instructions to reach target locations. Current VLN research mainly uses physically simplified simulators and low-mobility wheeled robots. These approaches fail to match the complex real-world conditions such as uneven terrains. This project aims to advance VLN by introducing Recurrent-VLN-Bert-Isaac, a novel imitation learning-based model architecture tailored for quadruped robots, and the VLN-Go2-Matterport dataset, a novel VLN dataset for navigation in high-fidelity indoor environments. This dataset enhances accessibility for researchers in Computer Vision and Natural Language Processing, and to bridge the gap between research and real-world deployment. Our promising experimental results demonstrate that the model effectively learns navigation policies from the dataset that are transferable to simulators. Additionally, We also explored LLM-based approaches, detailed in the Appendix. Together, this work contributes important and meaningful tools and insights to Embodied AI.
Project Overview
Vision-Language Navigation (VLN) stands as a pivotal challenge in Embodied AI, tasking robots with interpreting natural language directives (e.g., “Go to the kitchen and find the red chair”) to reach designated locations. Existing VLN methods often falter, limited by oversimplified simulators and wheeled robots unfit for rugged terrains. This project bridges these shortcomings by:
- Introducing Recurrent-VLN-Bert-Isaac, a transformer-based model engineered for quadruped robots, adept at navigating dynamic, intricate environments.
- Presenting the VLN-Go2-Matterport dataset, which encapsulates navigation data from a quadruped robot’s viewpoint in lifelike indoor settings.
Conducted in Nvidia Isaac Sim, our experiments demonstrate a 40% success rate across 10 test episodes, with an average progress of 53%, underscoring the model’s capacity to master effective navigation strategies. Additional LLM-based investigations further broaden the project’s horizons.
Key Contributions
- VLN as a Computer Vision-like Problem: We recast VLN as a series of image-driven decisions, releasing the VLN-Go2-Matterport dataset with a flexible collection pipeline to unite Embodied AI with Computer Vision and NLP research.
- Novel Architecture: Recurrent-VLN-Bert-Isaac fuses language and visual inputs into a latent representation framework, optimized for quadruped navigation.
- LLM-based Exploration: We evaluate LLM-based VLN strategies (detailed in the appendix), providing initial findings and avenues for future inquiry.
Dataset Description
The VLN-Go2-Matterport dataset is a vital asset for advancing Vision-Language Navigation (VLN) research, tailored specifically for quadruped robots. Unlike image-based datasets that limit agents to fixed viewpoints and discrete actions, or 3D-based datasets that demand impractical computational resources for end-to-end training, our dataset strikes a balance. It discretizes continuous environments while preserving the visual perspectives and agile dynamics of a quadruped robot, making it ideal for training end-to-end imitation learning-based VLN policies.
This dataset captures the actions and viewpoints of an expert Unitree Go2 robot navigating indoor environments reconstructed from the Matterport dataset [mattersim], rendered in Isaac Lab. Each of the 869 episodes represents a complete VLN task, where the robot follows an expert path under a pre-trained low-level locomotion policy, recording high-level navigation decisions as discrete actions. Each episode includes:
- Natural Language Instructions: Precise commands like “Go to the kitchen and find the red chair,” drawn from the VLN-CE-Isaac benchmark.
- RGB Images: A sequence of high-resolution images from the Go2’s camera, offering a first-person view of the environment.
- Depth Maps: Paired depth information with statistics outlined in Table 1, providing spatial context (e.g., minimum depth: 0.04 m, maximum: 39.36 m, mean: 2.02 m, standard deviation: 1.68 m).
- Discrete Actions: High-level decisions—”Move forward,” “Turn left,” or “Turn right”—serving as ground truth for imitation learning.
Table 1: Summary Statistics for Depth Maps (All values in meters)
| Statistic | Value |
|---|---|
| Minimum | 0.04 |
| Maximum | 39.36 |
| Mean | 2.02 |
| Standard Deviation | 1.68 |
Dataset Collection Pipeline
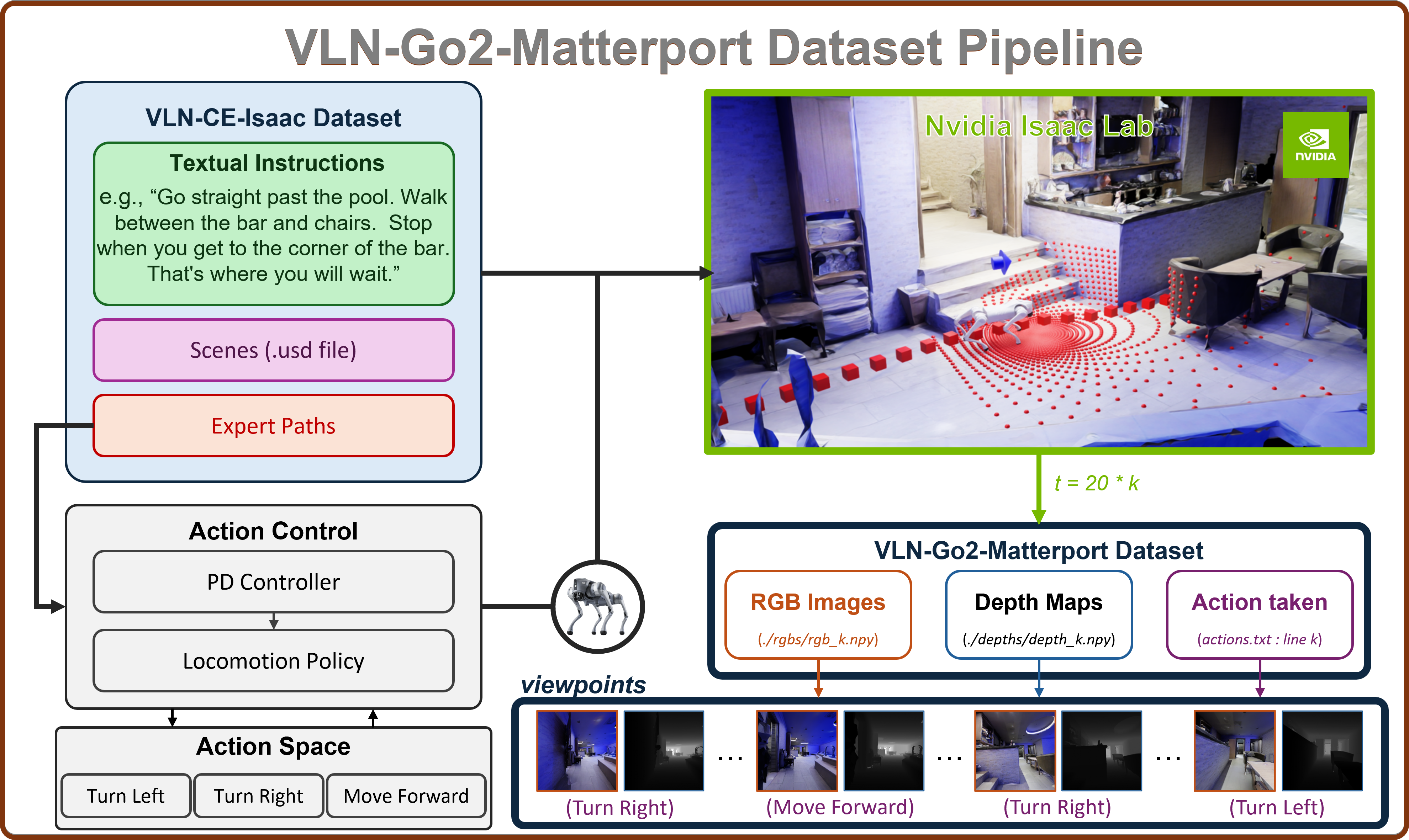
Figure 3: Pipeline for collecting the VLN-Go2-Matterport dataset.
The VLN-Go2-Matterport dataset’s creation is a carefully designed process, utilizing Isaac Lab and the VLN-CE-Isaac benchmark dataset. Illustrated in Figure 3, this pipeline ensures high-quality, consistent data reflective of a quadruped robot’s navigation process:
- PD Controller:
- A Proportional-Derivative (PD) controller acts as the expert navigator, choosing discrete actions to steer the Unitree Go2 along predefined expert paths.
- For a robot at position \(\mathbf{r} = [x_r, y_r, z_r]\) with orientation quaternion \(\mathbf{q} = [q_w, q_x, q_y, q_z]\), and a target point \(\mathbf{t} = [x_t, y_t, z_t]\) (look-ahead distance = 2 points), the relative position is calculated as \(\Delta\mathbf{p} = \mathbf{t} - \mathbf{r}\).
- The quaternion \(\mathbf{q}\) is converted to a rotation matrix \(\mathbf{R}\) (see appendix for details).
- The relative position transforms to the robot’s body frame: \(\Delta\mathbf{p}_{\text{body}} = \mathbf{R}^T \Delta\mathbf{p}\).
- Desired yaw is computed: \(\theta_d = \tan^{-1}\left(\frac{\Delta\mathbf{p}_{\text{body}}[1]}{\Delta\mathbf{p}_{\text{body}}[0]}\right)\).
- Desired yaw rate is determined: \(\omega_d = K_p \cdot \theta_d\), where \(K_p = \frac{0.5}{\pi}\).
- Action selection based on \(\omega_d\):
- If \(\omega_d \leq 0.05\) rad/s: “Move forward.”
- If \(\omega_d > 0.05\): “Turn left.”
- If \(\omega_d < -0.05\): “Turn right.”
- Action Execution:
- Actions map to velocity commands:
- “Move forward” → \((0.6, 0, 0)\) (linear x, y, angular z in m/s or rad/s).
- “Turn left” → \((0, 0, 0.5)\).
- “Turn right” → \((0, 0, -0.5)\).
- A pre-trained locomotion policy executes these commands, repeating each action for 20 simulation steps for smooth motion.
- Actions map to velocity commands:
- Data Collection:
- Every 20th simulation step, data is recorded:
- RGB image (PNG).
- Depth map (NumPy array).
- Discrete action taken.
- Every 20th simulation step, data is recorded:
- Episode Termination:
- Episodes end when the robot is within 1 meter of the goal (Euclidean distance in x-y plane) or after 3200 steps.
- Only successful episodes are saved, yielding 869 valid navigation trajectories.
Methodology
Figure 2: Recurrent-VLN-Bert-Isaac architecture, showing language-visual integration.
The Recurrent-VLN-Bert-Isaac model employs a transformer-based architecture to integrate natural language instructions with visual observations, enabling precise navigation decisions for quadruped robots. Its workflow includes:
Language Processing
At the episode’s outset, the instruction \(I\) (e.g., “Go to the kitchen”) is tokenized and embedded using a pre-trained BERT model:
\[\mathbf{E}_{\text{lang}} = \text{BertLayer}(\text{BertEmbeddings}(\text{tokenized_instruction}))\]The [CLS] token from \(\mathbf{E}_{\text{lang}}\) initializes the model’s state, updated recurrently with visual inputs.
Visual Processing
At each step, RGB images and depth maps are processed:
- RGB Features: Extracted via pre-trained ResNet-18: \(\mathbf{f}_{\text{RGB}} = \text{ResNet18}(\text{RGB_image}), \quad \mathbf{f}_{\text{RGB}} \in \mathbb{R}^{512}\)
- Depth Features: Extracted by a custom three-layer CNN: \(\mathbf{f}_{\text{depth}} = \text{DepthCNN}(\text{standardized_depth_map}), \quad \mathbf{f}_{\text{depth}} \in \mathbb{R}^{512}\)
These are concatenated and projected: \(\mathbf{f}_{\text{vis}} = [\mathbf{f}_{\text{RGB}}, \mathbf{f}_{\text{depth}}], \quad \mathbf{E}_{\text{vis}} = \text{LayerNorm}(\mathbf{W}_{\text{vis}} \mathbf{f}_{\text{vis}} + \mathbf{b}_{\text{vis}})\) where \(\mathbf{E}_{\text{vis}} \in \mathbb{R}^{1 \times 1 \times 768}\), and \(\mathbf{W}_{\text{vis}}, \mathbf{b}_{\text{vis}}\) are learnable parameters.
State Update and Action Prediction
The state updates via cross-attention (language-to-visual) and self-attention in the LXRTXLayer. The updated state \(\mathbf{S}_t\) is pooled: \(\mathbf{p}_t = \tanh(\mathbf{W}_{\text{pool}} \cdot \mathbf{S}_t''' + \mathbf{b}_{\text{pool}})\)
Actions are predicted: \(\mathbf{a}_t = \text{argmax}(\text{softmax}(\mathbf{W}_{\text{action}} \mathbf{p}_t + \mathbf{b}_{\text{action}}))\) where \(\mathbf{a}_t \in \{\text{"Move Forward"}, \text{"Turn Left"}, \text{"Turn Right"}\}\).
Training
Trained on the VLN-Go2-Matterport dataset (869 episodes) using imitation learning, the cross-entropy loss is: \(L = -\frac{1}{\sum_{i,t} M_{i,t}} \sum_{i,t} M_{i,t} \log P(a_{i,t} | s_{i,t})\) where \(M_{i,t}\) masks padded steps, optimized with AdamW and cosine annealing.
Setup and Demo
Follow the GitHub repository instructions to set up Nvidia Isaac Sim and run the demo via demo.py. Watch a sample run on YouTube.
Future Work
- LLM Integration: Enhancing VLN with Large Language Models.
- Spatial-Temporal Reasoning: Improving space-time reasoning.
- World and VLA Models: Exploring state-centric and vision-language-action models.
- Continual Learning: Enabling lifelong learning in dynamic environments.
Conclusion
This project propels Embodied AI forward with Recurrent-VLN-Bert-Isaac and the VLN-Go2-Matterport dataset, empowering quadruped robots to navigate complex settings using natural language. A 40% success rate in simulation and a scalable framework signal a promising path for real-world robotic applications.
BibTeX Citation
@article{wong2025advancing,
title={Advancing Vision-Language Navigation for Quadruped Robots: A Novel Model and Dataset for Real-World Applications},
author={WONG, Lik Hang Kenny},
year={2025}
}